
Readme
CoDet
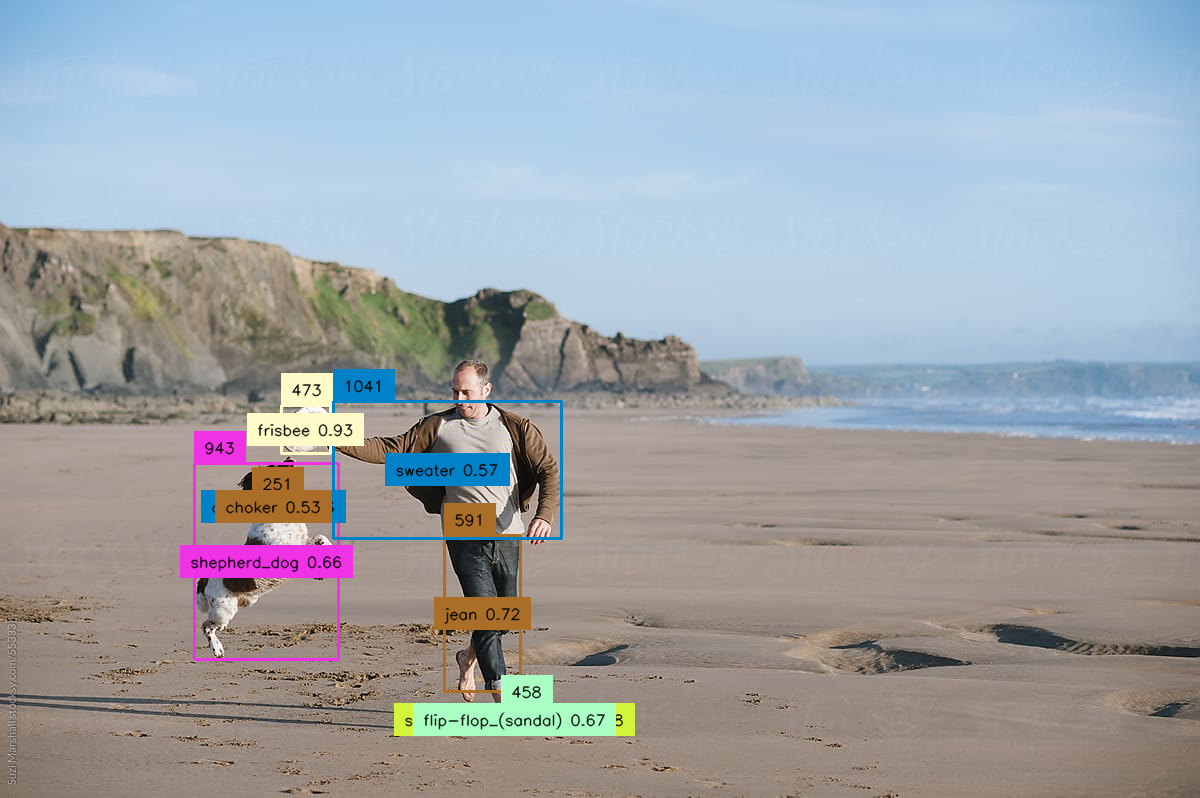
CoDet is an object detection model trained on the LVIS dataset. See the original repository and paper for details. Note that this model works as a typical object detection model with pre-defined object categories during inference but can be trained in an open-vocabulary manner with image-caption pairs.
How to use the API
To use CoDet, simply upload the image you would like to detect objects for and enter a confidence threshold to filter out detections. The API returns a json file with the bounding box (x1, y1, x2, y2), class id, class name and confidence score of each detection.
Refer to the class names file in the cog repository for a full list of LVIS classes.
References
@inproceedings{ma2023codet,
title={CoDet: Co-Occurrence Guided Region-Word Alignment for Open-Vocabulary Object Detection},
author={Ma, Chuofan and Jiang, Yi and Wen, Xin and Yuan, Zehuan and Qi, Xiaojuan},
booktitle={Advances in Neural Information Processing Systems},
year={2023}
}