Explore

Fine-tune FLUX fast
Customize FLUX.1 [dev] with the fast FLUX trainer on Replicate
Train the model to recognize and generate new concepts using a small set of example images, for specific styles, characters, or objects. It's fast (under 2 minutes), cheap (under $2), and gives you a warm, runnable model plus LoRA weights to download.
Featured models

luma / reframe-video
Change the aspect ratio of any video up to 30 seconds long, outputs will be 720p

google / imagen-4-fast
Use this fast version of Imagen 4 when speed and cost are more important than quality

google / imagen-4-ultra
Use this ultra version of Imagen 4 when quality matters more than speed and cost

google / imagen-4
Google's Imagen 4 flagship model

replicate / fast-flux-trainer
Train subjects or styles faster than ever

google / veo-3
Sound on: Google’s flagship Veo 3 text to video model, with audio

black-forest-labs / flux-kontext-pro
A state-of-the-art text-based image editing model that delivers high-quality outputs with excellent prompt following and consistent results for transforming images through natural language

black-forest-labs / flux-kontext-max
A premium text-based image editing model that delivers maximum performance and improved typography generation for transforming images through natural language prompts

ideogram-ai / ideogram-v3-turbo
Turbo is the fastest and cheapest Ideogram v3. v3 creates images with stunning realism, creative designs, and consistent styles
Official models
Official models are always on, maintained, and have predictable pricing.














I want to…
Generate images
Models that generate images from text prompts
Make videos with Wan2.1
Generate videos with Wan2.1, the fastest and highest quality open-source video generation model.
Generate videos
Models that create and edit videos
Caption images
Models that generate text from images
Transcribe speech
Models that convert speech to text
Use the FLUX family of models
The FLUX family of text-to-image models from Black Forest Labs
Remove backgrounds
Models that remove backgrounds from images and videos
Restore images
Models that improve or restore images by deblurring, colorization, and removing noise
Caption videos
Models that generate text from videos
Edit images
Tools for manipulating images.
Use a face to make images
Make realistic images of people instantly
Get embeddings
Models that generate embeddings from inputs
Generate speech
Convert text to speech
Generate music
Models to generate and modify music
Generate text
Models that can understand and generate text
Use handy tools
Toolbelt-type models for videos and images.
Upscale images
Upscaling models that create high-quality images from low-quality images
Use official models
Official models are always on, maintained, and have predictable pricing.
Enhance videos
Models that enhance videos with super-resolution, sound effects, motion capture and other useful production effects.
Detect objects
Models that detect or segment objects in images and videos.
Sing with voices
Voice-to-voice cloning and musical prosody
Make 3D stuff
Models that generate 3D objects, scenes, radiance fields, textures and multi-views.
Chat with images
Ask language models about images
Extract text from images
Optical character recognition (OCR) and text extraction
Use FLUX fine-tunes
Browse the diverse range of fine-tunes the community has custom-trained on Replicate
Control image generation
Guide image generation with more than just text. Use edge detection, depth maps, and sketches to get the results you want.
Popular models

SDXL-Lightning by ByteDance: a fast text-to-image model that makes high-quality images in 4 steps

multilingual-e5-large: A multi-language text embedding model

This is an optimised version of the FLUX.1 [schnell] model from Black Forest Labs made with Pruna. We achieve a ~3x speedup over the original model with minimal quality loss.



Return CLIP features for the clip-vit-large-patch14 model

whisper-large-v3, incredibly fast, powered by Hugging Face Transformers! 🤗
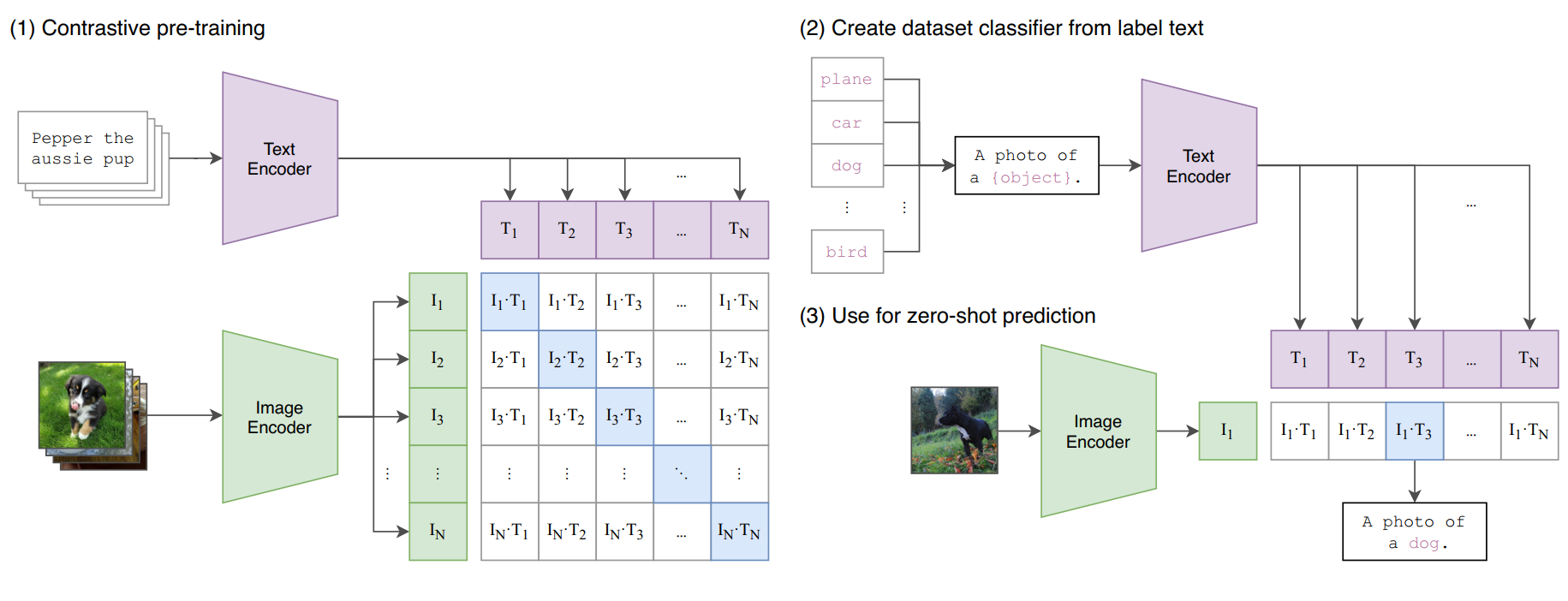
Generate CLIP (clip-vit-large-patch14) text & image embeddings
Latest models



Segment foreground objects with high resolution and matting, using InSPyReNet



Three models in one Cog: Absolute Reality v1.8.1, DreamShaper v8 and Meina V4


Source: gradientai/Llama-3-8B-Instruct-Gradient-4194k ✦ Quant: solidrust/Llama-3-8B-Instruct-Gradient-4194k-AWQ ✦ Extending LLama-3 8B's context length from 8k to 4194K

CLIP Interrogator for SDXL optimizes text prompts to match a given image

📖 PuLID: Pure and Lightning ID Customization via Contrastive Alignment


PaliGemma 3B, an open VLM by Google, pre-trained with 224*224 input images and 128 token input/output text sequences

A model which generates text in response to an input image and prompt.

Generate image with transparent background
Yi-1.5 is continuously pre-trained on Yi with a high-quality corpus of 500B tokens and fine-tuned on 3M diverse fine-tuning samples

InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view LRMs

Blip 3 / XGen-MM, Answers questions about images ({blip3,xgen-mm}-phi3-mini-base-r-v1)

Dolphin is uncensored. I have filtered the dataset to remove alignment and bias. This makes the model more compliant.

return CLIP features for the dfn5b-clip-vit-h-14-384, current highest average perf. in openclip models leaderboard.

Dolphin is uncensored. I have filtered the dataset to remove alignment and bias. This makes the model more compliant.

Dolphin is uncensored. I have filtered the dataset to remove alignment and bias. This makes the model more compliant.



BLIP3(XGen-MM) is a series of foundational Large Multimodal Models (LMMs) developed by Salesforce AI Research

Transcribe audios using OpenAI's Whisper with stabilizing timestamps by stable-ts python package.


Use a face to instantly make images. Uses SDXL Lightning checkpoints.

Dark Sushi Mix 2.25D Model with vae-ft-mse-840000-ema (Text2Img, Img2Img and Inpainting)

DeepSeek LLM, an advanced language model comprising 67 billion parameters. Trained from scratch on a vast dataset of 2 trillion tokens in both English and Chinese



A llama-3 based moderation and safeguarding language model


InstantID. ControlNets. More base SDXL models. And the latest ByteDance's ⚡️SDXL-Lightning !⚡️

The img2img pipeline that makes an anime-style image of a person. It uses one of sd1.5 models as a base, depth-estimation as a ControleNet and IPadapter model for face consistency.

Consistent Self-Attention for Long-Range Image and Video Generation


StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation

Robust face restoration algorithm for old photos / AI-generated faces (adapted to work with video inputs)



Just some good ole beautifulsoup scrapping URL magic. (some sites don't work as they block scrapping, but still useful)





PyTorch implementation of AnimeGAN for fast photo animation