Explore

Fine-tune FLUX fast
Customize FLUX.1 [dev] with the fast FLUX trainer on Replicate
Train the model to recognize and generate new concepts using a small set of example images, for specific styles, characters, or objects. It's fast (under 2 minutes), cheap (under $2), and gives you a warm, runnable model plus LoRA weights to download.
Featured models

luma / reframe-video
Change the aspect ratio of any video up to 30 seconds long, outputs will be 720p

google / imagen-4-fast
Use this fast version of Imagen 4 when speed and cost are more important than quality

google / imagen-4-ultra
Use this ultra version of Imagen 4 when quality matters more than speed and cost

google / imagen-4
Google's Imagen 4 flagship model

replicate / fast-flux-trainer
Train subjects or styles faster than ever

google / veo-3
Sound on: Google’s flagship Veo 3 text to video model, with audio

black-forest-labs / flux-kontext-pro
A state-of-the-art text-based image editing model that delivers high-quality outputs with excellent prompt following and consistent results for transforming images through natural language

black-forest-labs / flux-kontext-max
A premium text-based image editing model that delivers maximum performance and improved typography generation for transforming images through natural language prompts

ideogram-ai / ideogram-v3-turbo
Turbo is the fastest and cheapest Ideogram v3. v3 creates images with stunning realism, creative designs, and consistent styles
Official models
Official models are always on, maintained, and have predictable pricing.














I want to…
Generate images
Models that generate images from text prompts
Make videos with Wan2.1
Generate videos with Wan2.1, the fastest and highest quality open-source video generation model.
Generate videos
Models that create and edit videos
Caption images
Models that generate text from images
Transcribe speech
Models that convert speech to text
Use the FLUX family of models
The FLUX family of text-to-image models from Black Forest Labs
Remove backgrounds
Models that remove backgrounds from images and videos
Restore images
Models that improve or restore images by deblurring, colorization, and removing noise
Caption videos
Models that generate text from videos
Edit images
Tools for manipulating images.
Use a face to make images
Make realistic images of people instantly
Get embeddings
Models that generate embeddings from inputs
Generate speech
Convert text to speech
Generate music
Models to generate and modify music
Generate text
Models that can understand and generate text
Use handy tools
Toolbelt-type models for videos and images.
Upscale images
Upscaling models that create high-quality images from low-quality images
Use official models
Official models are always on, maintained, and have predictable pricing.
Enhance videos
Models that enhance videos with super-resolution, sound effects, motion capture and other useful production effects.
Detect objects
Models that detect or segment objects in images and videos.
Sing with voices
Voice-to-voice cloning and musical prosody
Make 3D stuff
Models that generate 3D objects, scenes, radiance fields, textures and multi-views.
Chat with images
Ask language models about images
Extract text from images
Optical character recognition (OCR) and text extraction
Use FLUX fine-tunes
Browse the diverse range of fine-tunes the community has custom-trained on Replicate
Control image generation
Guide image generation with more than just text. Use edge detection, depth maps, and sketches to get the results you want.
Popular models

SDXL-Lightning by ByteDance: a fast text-to-image model that makes high-quality images in 4 steps
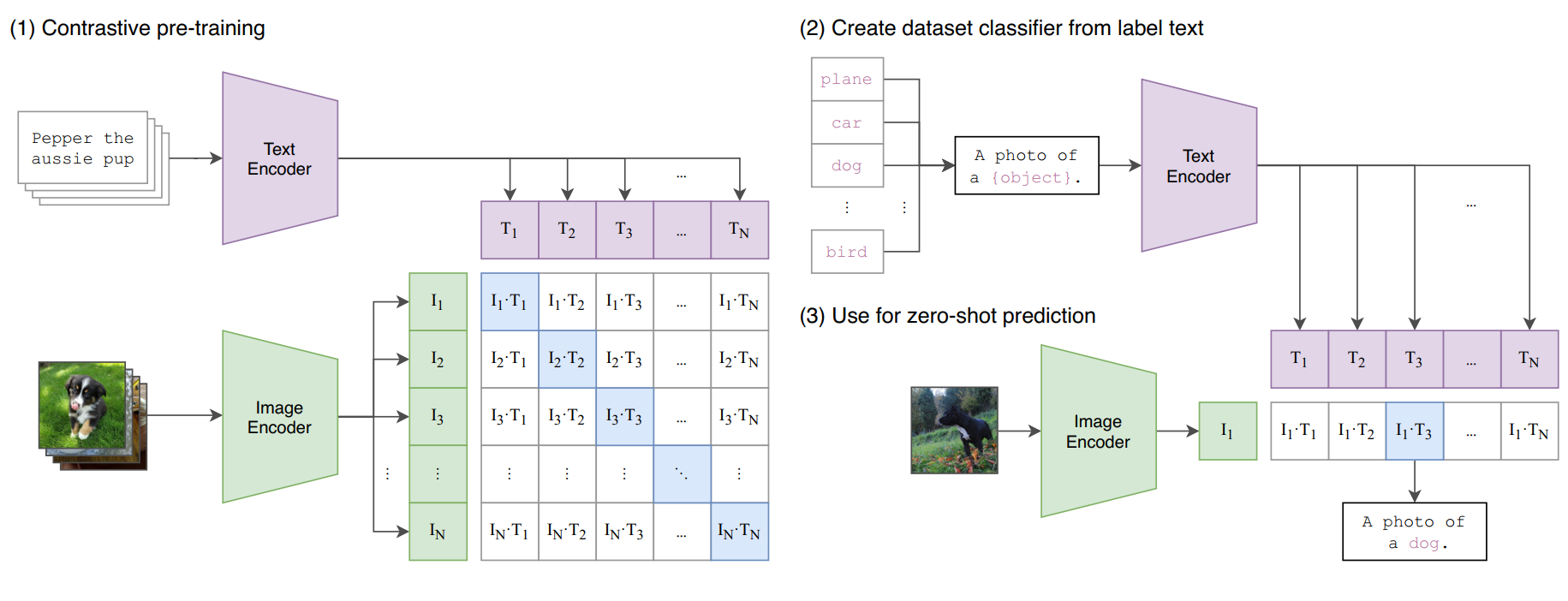
Generate CLIP (clip-vit-large-patch14) text & image embeddings


Return CLIP features for the clip-vit-large-patch14 model

This is an optimised version of the FLUX.1 [schnell] model from Black Forest Labs made with Pruna. We achieve a ~3x speedup over the original model with minimal quality loss.

whisper-large-v3, incredibly fast, powered by Hugging Face Transformers! 🤗


Latest models



Undi95's FlatDolphinMaid 8x7B Mixtral Merge, GGUF Q5_K_M quantized by TheBloke.

InstantID : Zero-shot Identity-Preserving Generation in Seconds with ⚡️LCM-LoRA⚡️. Using AlbedoBase-XL v2.0 as base model.

Take an image and an audio file and create a video clip

amrul-hzz's fine-tuned version of vit-base-patch16-224-in21k for watermark image detection





(Research only) Moondream1 is a vision language model that performs on par with models twice its size

Proteus v0.2 shows subtle yet significant improvements over Version 0.1. It demonstrates enhanced prompt understanding that surpasses MJ6, while also approaching its stylistic capabilities.


Undi95's Borealis 10.7B Mistral DPO Finetune, GGUF Q5_K_M quantized by Undi95.

InstantID : Zero-shot Identity-Preserving Generation in Seconds. Using Juggernaut-XL v8 as the base model to encourage photorealism

InstantID : Zero-shot Identity-Preserving Generation in Seconds. Using Dreamshaper-XL as the base model to encourage artistic generations

Highly practical solution for robust monocular depth estimation by training on a combination of 1.5M labeled images and 62M+ unlabeled images

SigLIP proposes to replace the loss function used in CLIP by a simple pairwise sigmoid loss

WizardCoder: Empowering Code Large Language Models with Evol-Instruct


Nebul.Redmond - Stable Diffusion SD XL Finetuned Model

Create photos, paintings and avatars for anyone in any style within seconds. (Stylization version)

Video Smoother: AMT All-Pairs Multi-Field Transforms for Efficient Frame Interpolation



NeuralBeagle14-7B is (probably) the best 7B model you can find!


Source: SciPhi/Sensei-7B-V1 ✦ Quant: TheBloke/Sensei-7B-V1-AWQ ✦ Sensei is specialized in performing RAG over detailed web search results

Source: WhiteRabbitNeo/WhiteRabbitNeo-13B-v1 ✦ TheBloke/WhiteRabbitNeo-13B-AWQ ✦ WhiteRabbitNeo is a model series that can be used for offensive and defensive cybersecurity

PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding

Create photos, paintings and avatars for anyone in any style within seconds.

Third party Fooocus replicate model with preset 'anime'

Third party Fooocus replicate model with preset 'realistic'


An Open Source text-to-speech system built by inverting Whisper

Unofficial Re-Trained AnimateAnyone (Image + DWPose Video → Animated Video of Image)


Photorealism with RealVisXL V3.0 Turbo based on SDXL


Implementation of Realistic Vision v5.1 to conjure up images of the potential baby using a single photo from each parent

MAGNeT: Masked Audio Generation using a Single Non-Autoregressive Transformer



Source: allenai/digital-socrates-13b ✦ Quant: TheBloke/digital-socrates-13B-AWQ ✦ Digital Socrates is an open-source, automatic explanation-critiquing model

Source: Unbabel/TowerInstruct-7B-v0.1 ✦ Quant: TheBloke/TowerInstruct-7B-v0.1-AWQ ✦ This model is trained to handle several translation-related tasks, such as general machine translation, gramatical error correction, and paraphrase generation

Improving the Stability of Diffusion Models for Content Consistent Super-Resolution

ProteusV0.1 uses OpenDalleV1.1 as a base and further refines prompt adherence and stylistic capabilities to a measurable degree

Great image quality, good old SDXL with a new and improved Tile refiner.
