
Readme
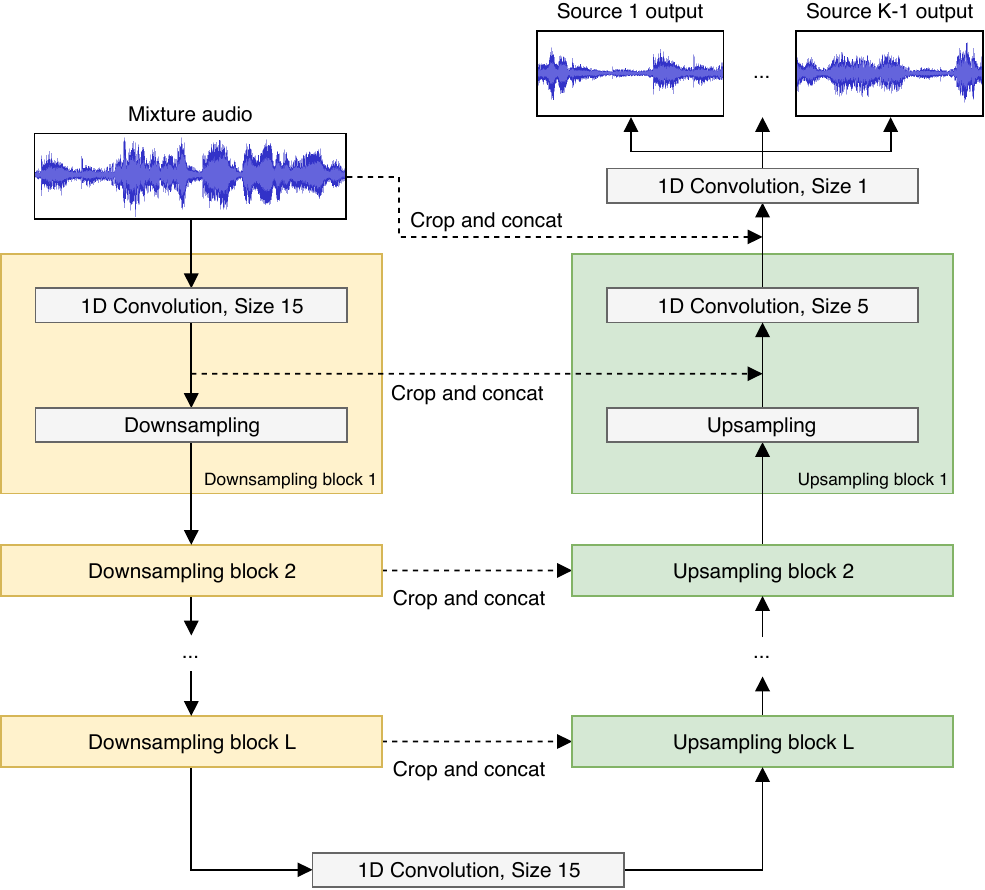
The Wave-U-Net is a convolutional neural network applicable to audio source separation tasks, which works directly on the raw audio waveform, presented in this paper.
The Wave-U-Net is an adaptation of the U-Net architecture to the one-dimensional time domain to perform end-to-end audio source separation. Through a series of downsampling and upsampling blocks, which involve 1D convolutions combined with a down-/upsampling process, features are computed on multiple scales/levels of abstraction and time resolution, and combined to make a prediction.
See the diagram below for a summary of the network architecture.
This is an improved version, implemented in PyTorch.