
















Readme
Infinity: Scaling Bitwise AutoRegressive Modeling for High-Resolution Image Synthesis
📖 Introduction
We present Infinity, a Bitwise Visual AutoRegressive Modeling capable of generating high-resolution and photorealistic images. Infinity redefines visual autoregressive model under a bitwise token prediction framework with an infinite-vocabulary tokenizer & classifier and bitwise self-correction. Theoretically scaling the tokenizer vocabulary size to infinity and concurrently scaling the transformer size, our method significantly unleashes powerful scaling capabilities. Infinity sets a new record for autoregressive text-to-image models, outperforming top-tier diffusion models like SD3-Medium and SDXL. Notably, Infinity surpasses SD3-Medium by improving the GenEval benchmark score from 0.62 to 0.73 and the ImageReward benchmark score from 0.87 to 0.96, achieving a win rate of 66%. Without extra optimization, Infinity generates a high-quality 1024×1024 image in 0.8 seconds, making it 2.6× faster than SD3-Medium and establishing it as the fastest text-to-image model.
🔥 Redefines VAR under a bitwise token prediction framework 🚀:
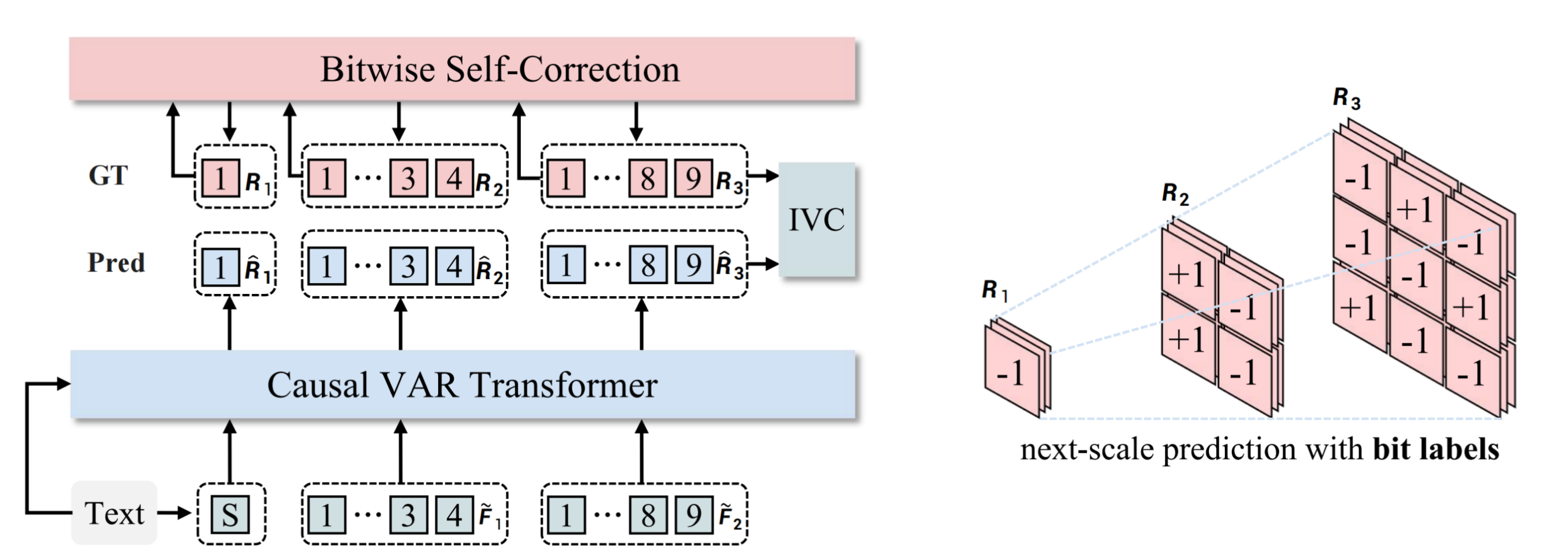
Infinite-Vocabulary Tokenizer✨: We proposes a new bitwise multi-scale residual quantizer, which significantly reduces memory usage, enabling the training of extremely large vocabulary, e.g. $V_d = 2^{32}$ or $V_d = 2^{64}$.
Infinite-Vocabulary Classifier✨: Conventional classifier predicts $2^d$ indices. IVC predicts $d$ bits instead. Slight perturbations to near-zero values in continuous features cause a complete change of indices labels. Bit labels change subtly and still provide steady supervision. Besides, if d = 32 and h = 2048, a conventional classifier requires 8.8T parameters. IVC only requires 0.13M.
Bitwise Self-Correction✨: Teacher-forcing training in AR brings severe train-test discrepancy. It lets the transformer only refine features without recognizing and correcting mistakes. Mistakes will be propagated and amplified, finally messing up generated images. We propose Bitwise Self-Correction (BSC) to mitigate the train-test discrepancy.
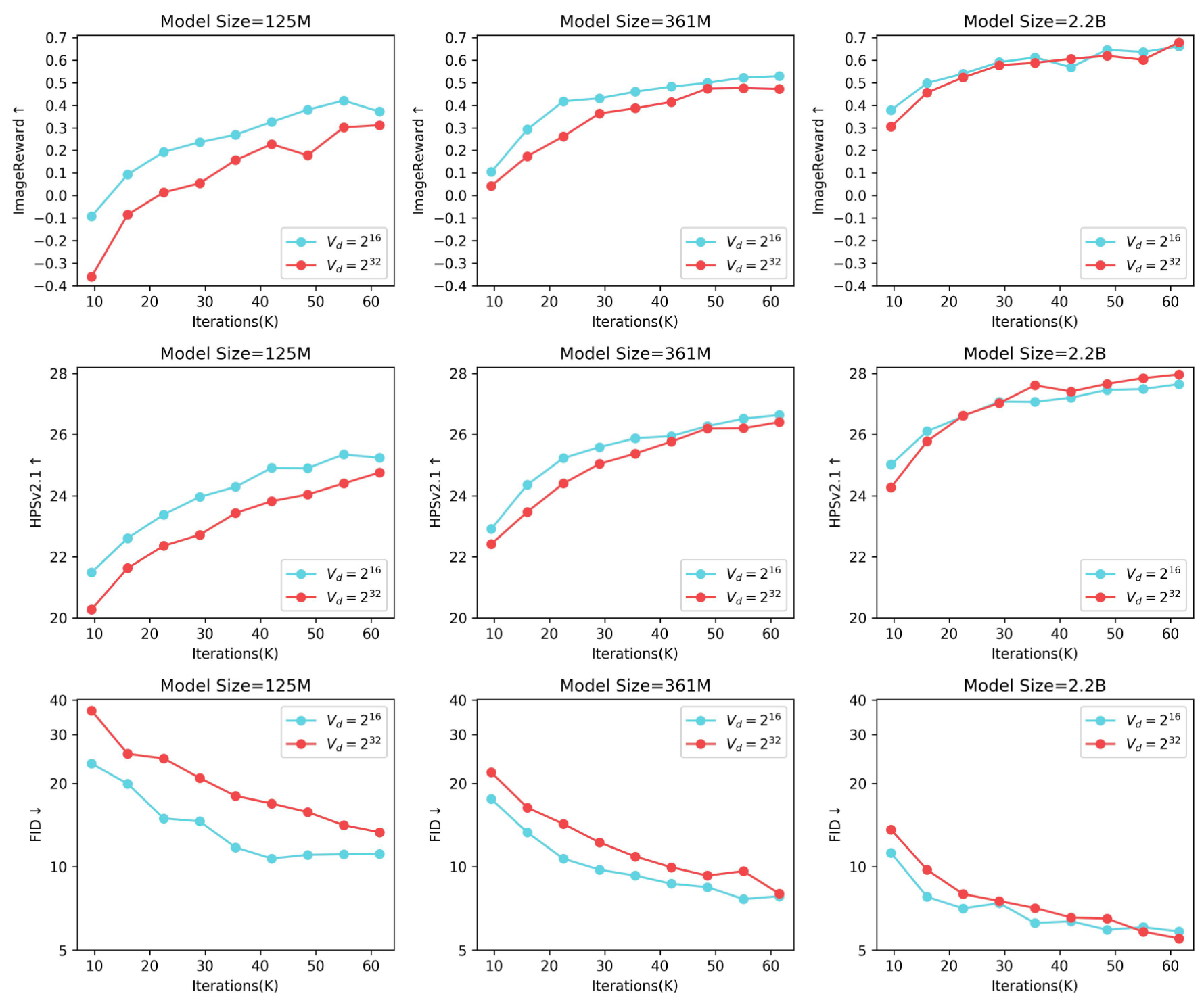
🔥 Scaling Vocabulary benefits Reconstruction and Generation 📈:
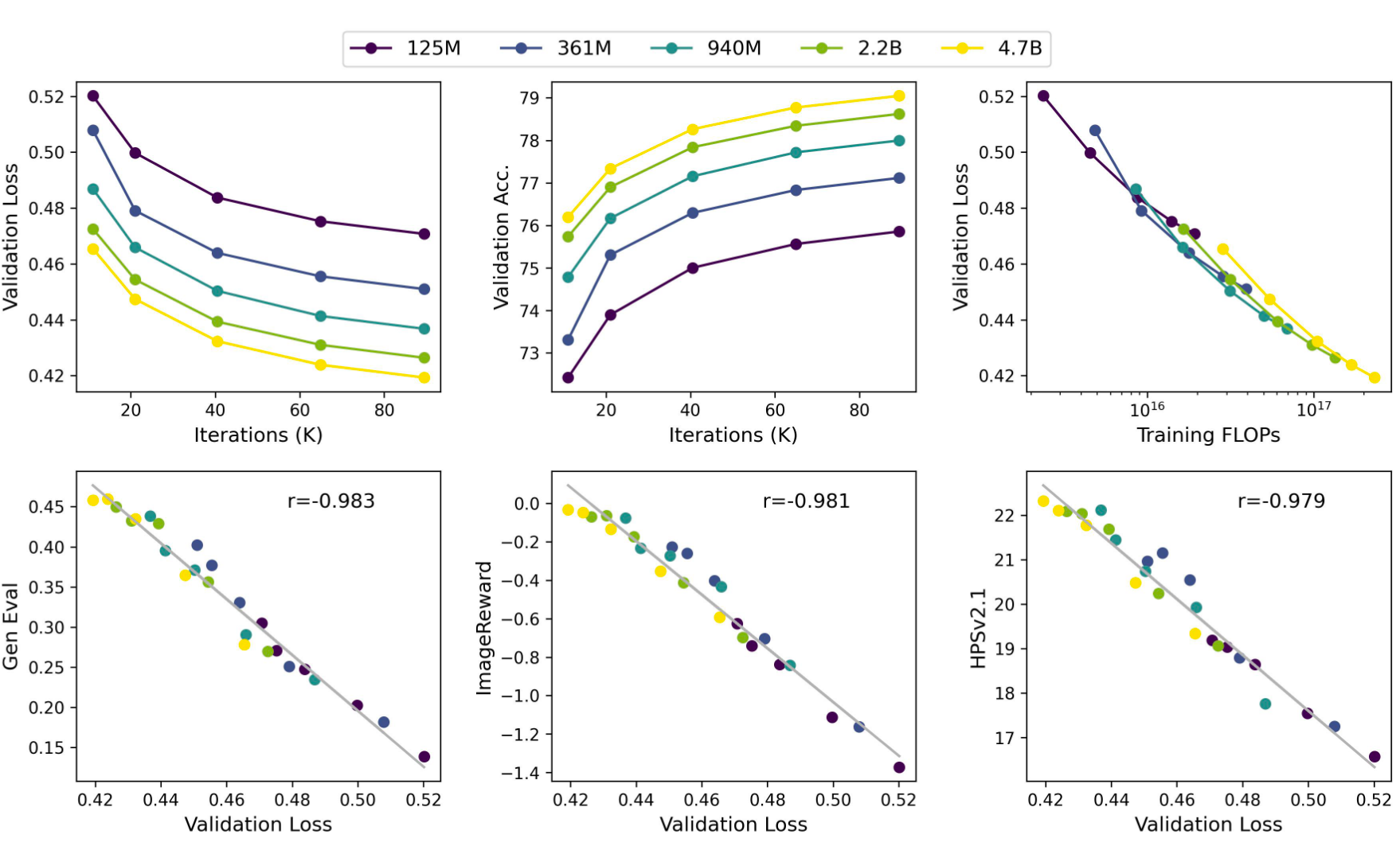
🔥 Discovering Scaling Laws in Infinity transformers 📈:
Citation
If our work assists your research, feel free to give us a star ⭐ or cite us using:
@misc{han2024infinityscalingbitwiseautoregressive,
title={Infinity: Scaling Bitwise AutoRegressive Modeling for High-Resolution Image Synthesis},
author={Jian Han and Jinlai Liu and Yi Jiang and Bin Yan and Yuqi Zhang and Zehuan Yuan and Bingyue Peng and Xiaobing Liu},
year={2024},
eprint={2412.04431},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2412.04431},
}
License
This project is licensed under the MIT License - see the LICENSE file for details.