

Readme
Recognize Anything with Grounded-Segment-Anything
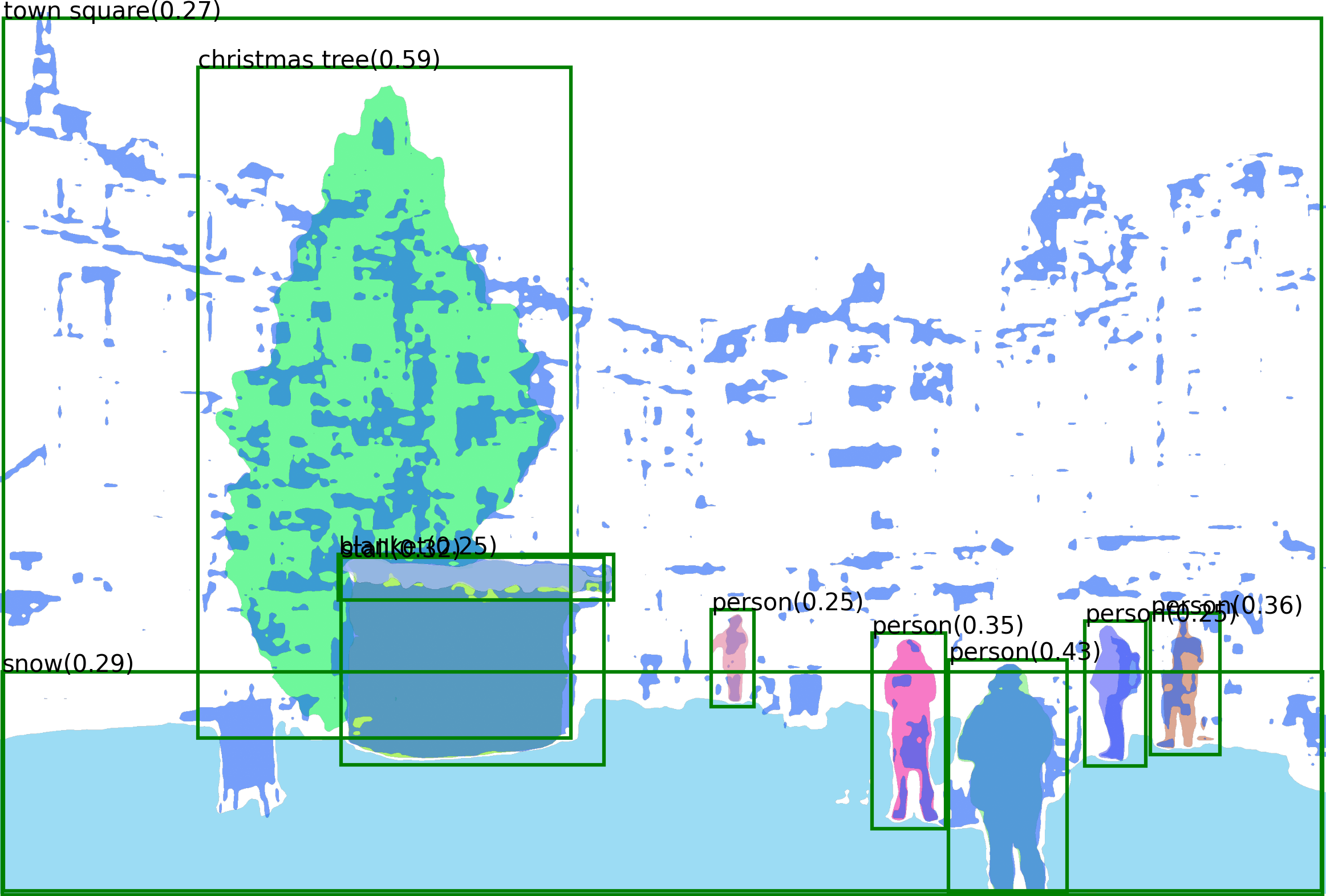
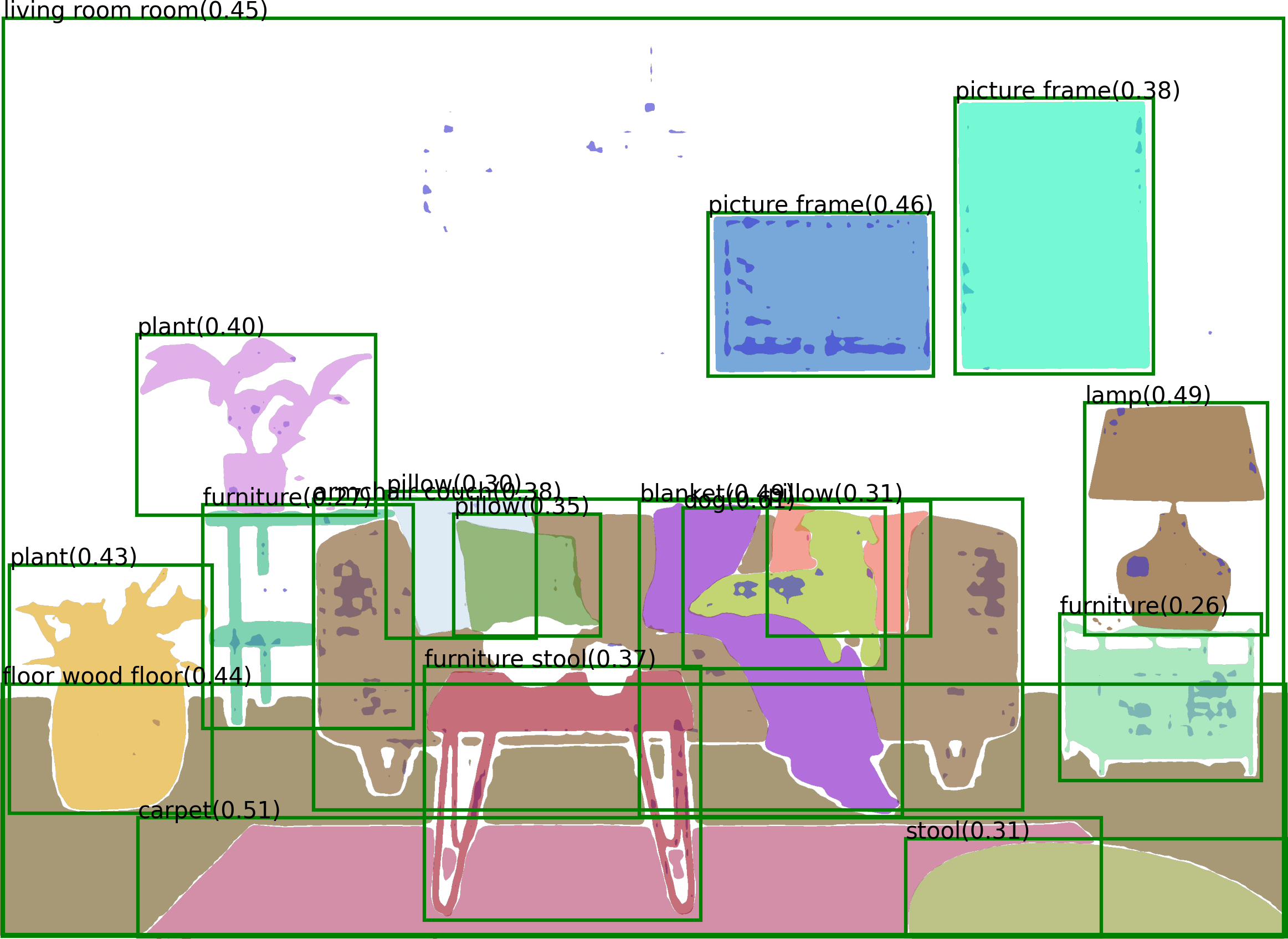
Recognize Anything Model (RAM) is an image tagging model, which can recognize any common category with high accuracy.
Highlight of RAM
RAM is a strong image tagging model, which can recognize any common category with high accuracy. - Strong and general. RAM exhibits exceptional image tagging capabilities with powerful zero-shot generalization; - RAM showcases impressive zero-shot performance, significantly outperforming CLIP and BLIP. - RAM even surpasses the fully supervised manners (ML-Decoder). - RAM exhibits competitive performance with the Google tagging API. - Reproducible and affordable. RAM requires Low reproduction cost with open-source and annotation-free dataset; - Flexible and versatile. RAM offers remarkable flexibility, catering to various application scenarios.
 |
RAM significantly improves the tagging ability based on the Tag2text framework. - Accuracy. RAM utilizes a data engine to generate additional annotations and clean incorrect ones, higher accuracy compared to Tag2Text. - Scope. RAM upgrades the number of fixed tags from 3,400+ to 6,400+ (synonymous reduction to 4,500+ different semantic tags), covering more valuable categories.
Citation
If you find our work to be useful for your research, please consider citing.
@article{zhang2023recognize,
title={Recognize Anything: A Strong Image Tagging Model},
author={Zhang, Youcai and Huang, Xinyu and Ma, Jinyu and Li, Zhaoyang and Luo, Zhaochuan and Xie, Yanchun and Qin, Yuzhuo and Luo, Tong and Li, Yaqian and Liu, Shilong and others},
journal={arXiv preprint arXiv:2306.03514},
year={2023}
}
@article{liu2023grounding,
title={Grounding dino: Marrying dino with grounded pre-training for open-set object detection},
author={Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Hao and Yang, Jie and Li, Chunyuan and Yang, Jianwei and Su, Hang and Zhu, Jun and others},
journal={arXiv preprint arXiv:2303.05499},
year={2023}
}