
✨SAM 2: Segment Anything v2 for Videos🎥
NOTE: This implementation now supports video inputs and offers the large variant of the model.
About
Implementation of SAM 2, a model for segmenting objects in videos and images using various prompts. This version fully supports video inputs.
How to Use SAM2 Inputs
SAM2 uses four main inputs to know where and what to look for in your video. Understanding how these work together is key to getting the results you want.
1. click_coordinates
This tells SAM2 exactly where to look in the video. It sets the number of points for all inputs.
- Format:
'[x,y],[x,y],[x,y]' - Example:
'[100,100],[200,200],[300,300]' - This means: Look at 3 points because we have 3
[x,y]coordinates - Important: The number of
[x,y]pairs here determines how many points SAM2 will consider
2. click_labels
This tells SAM2 if each point is part of the object (foreground) or not (background).
- Format:
'1,0,1' 1means foreground (part of the object)0means background (not part of the object)- If fewer labels than points in
click_coordinates, the last value repeats
3. click_frames
This tells SAM2 which frame of the video each point is in.
- Format:
'0,10,20' - If fewer frame numbers than points in
click_coordinates, the last value repeats - If no frames given, all points are assumed to be on frame
0
4. click_object_ids
This gives names to the objects SAM2 is looking at. This is crucial for distinguishing between similar objects.
- Format:
'person,dog,cat' - If fewer names than points in
click_coordinates, it generates names like ‘object_1','object_2',... - Important: The object IDs determine how SAM2 groups points into objects
Why Object IDs Matter:
- Same ID = Same Object: If you give the same ID to multiple points, SAM2 assumes they’re part of the same object, even if they’re far apart.
- Different IDs = Different Objects: Using different IDs tells SAM2 these are separate objects, even if they look similar.
Example: Two Birds in a Video
-
Scenario 1: Same ID
click_coordinates: '[100,100],[300,300]' click_object_ids: 'bird,bird'Result: SAM2 might try to connect these points, assuming it’s one large or oddly shaped bird. -
Scenario 2: Different IDs
click_coordinates: '[100,100],[300,300]' click_object_ids: 'bird_1,bird_2'Result: SAM2 will treat these as two separate birds, creating distinct masks for each.
Using IDs to Refine Masks
- If a single object isn’t masked properly, you can add more points with the same ID to refine the mask.
click_coordinates: '[100,100],[150,150],[200,200]' click_object_ids: 'dog,dog,dog'This tells SAM2 “These are all part of the same dog” and helps refine the dog’s mask.
How They Work Together
Let’s look at an example to see how all inputs work together:
Example: Multiple Objects (5 points)
click_coordinates: '[100,100],[200,200],[300,300],[400,400],[500,500]'
click_labels: '1,1,0,1,1'
click_frames: '0,0,10,20,20'
click_object_ids: 'dog,dog,background,cat,cat'
This means (5 points because we have 5 [x,y] pairs):
1. Look for a dog at (100,100) in frame 0. It’s part of the object we want.
2. Look for the same dog at (200,200) in frame 0. It’s part of the object we want.
3. Look at (300,300) in frame 10. It’s background, not part of any object we want.
4. Look for a cat at (400,400) in frame 20. It’s part of an object we want.
5. Look for the same cat at (500,500) in frame 20. It’s part of the object we want.
SAM2 will create two separate masks: one for the dog (points 1 and 2) and one for the cat (points 4 and 5).
Important Things to Remember
- The number of
[x,y]pairs inclick_coordinatesdetermines how many points SAM2 considers. - Object IDs help SAM2 understand which points belong to the same object, even across different frames.
- Use different object IDs for separate objects, even if they’re the same type of thing (like two different birds).
- Use the same object ID to refine or extend the mask of a single object.
- If you provide fewer values for labels, frames, or object IDs than you have coordinates, SAM2 will repeat the last value to fill in the rest.
- SAM2 ignores spaces in your input, so
'1, 0, 1'is the same as'1,0,1'.
By understanding these inputs and how they work together, you can guide SAM2 to accurately identify and mask objects in your video!
Limitations
- Performance may vary depending on video quality and complexity.
- Very fast or complex motions in videos might be challenging.
- Higher resolutions provide more detail but require more processing time.
SAM 2 is a 🔥 model developed by Meta AI Research. It excels at segmenting objects in both images and videos with various types of prompts.
Core Model
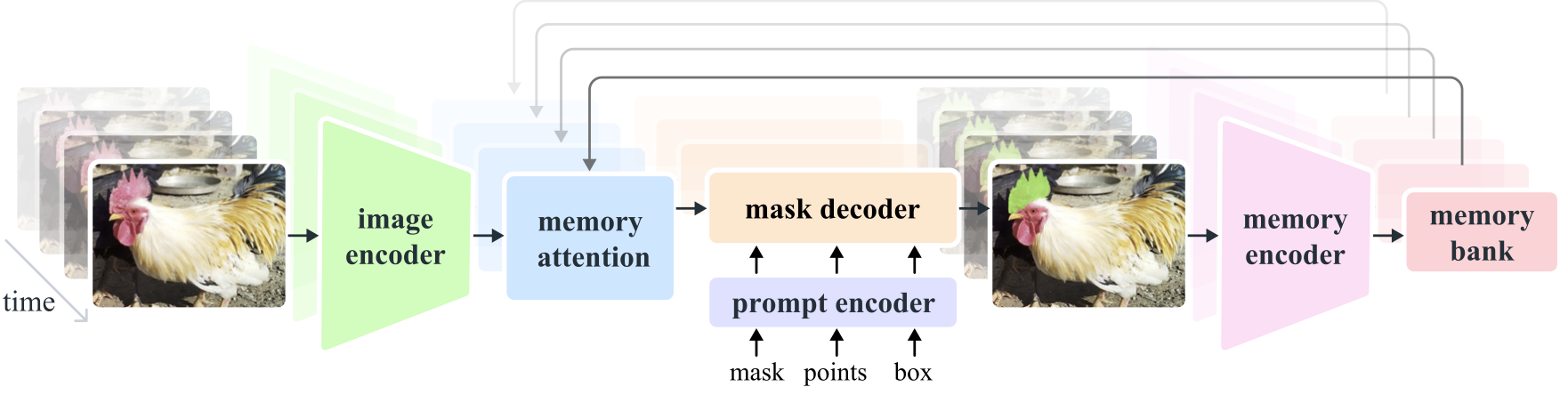
An overview of the SAM 2 framework.
SAM 2 uses a transformer architecture with streaming memory for real-time video processing. It builds on the original SAM model, extending its capabilities to video.
For more technical details, check out the Research paper.
Safety
⚠️ Users should be aware of potential ethical implications: - Ensure you have the right to use input images and videos, especially those featuring identifiable individuals. - Be responsible about generated content to avoid potential misuse. - Be cautious about using copyrighted material as inputs without permission.
Support
All credit goes to the Meta AI Research team
Citation
@article{ravi2024sam2,
title={SAM 2: Segment Anything in Images and Videos},
author={Ravi, Nikhila and Gabeur, Valentin and Hu, Yuan-Ting and Hu, Ronghang and Ryali, Chaitanya and Ma, Tengyu and Khedr, Haitham and R{\"a}dle, Roman and Rolland, Chloe and Gustafson, Laura and Mintun, Eric and Pan, Junting and Alwala, Kalyan Vasudev and Carion, Nicolas and Wu, Chao-Yuan and Girshick, Ross and Doll{\'a}r, Piotr and Feichtenhofer, Christoph},
journal={arXiv preprint},
year={2024}
}