
Readme
Model Card
SAM (Small Agentic Model), a 7B model that demonstrates impressive reasoning abilities despite its smaller size. SAM-7B has outperformed existing SoTA models on various reasoning benchmarks, including GSM8k and ARC-C.
For full details of this model please read our release blog post.
Key Contributions
- SAM-7B outperforms GPT 3.5, Orca, and several other 70B models on multiple reasoning benchmarks, including ARC-C and GSM8k.
- Interestingly, despite being trained on a 97% smaller dataset, SAM-7B surpasses Orca-13B on GSM8k.
- All responses in our fine-tuning dataset are generated by open-source models without any assistance from state-of-the-art models like GPT-3.5 or GPT-4.
Training
- Trained by: SuperAGI Team
- Hardware: NVIDIA 6 x H100 SxM (80GB)
- Model used: Mistral 7B
- Duration of finetuning: 4 hours
- Number of epochs: 1
- Batch size: 16
- Learning Rate: 2e-5
- Warmup Ratio: 0.1
- Optmizer: AdamW
- Scheduler: Cosine
Example Prompt
The template used to build a prompt for the Instruct model is defined as follows:
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
Note that <s> and </s> are special tokens for beginning of string (BOS) and end of string (EOS) while [INST] and [/INST] are regular strings.
Evaluation
These benchmarks show that our model has improved reasoning as compared to orca 2-7b, orca 2-13b and GPT-3.5.
Despite being smaller in size, we show better multi-hop reasoning, as shown below:
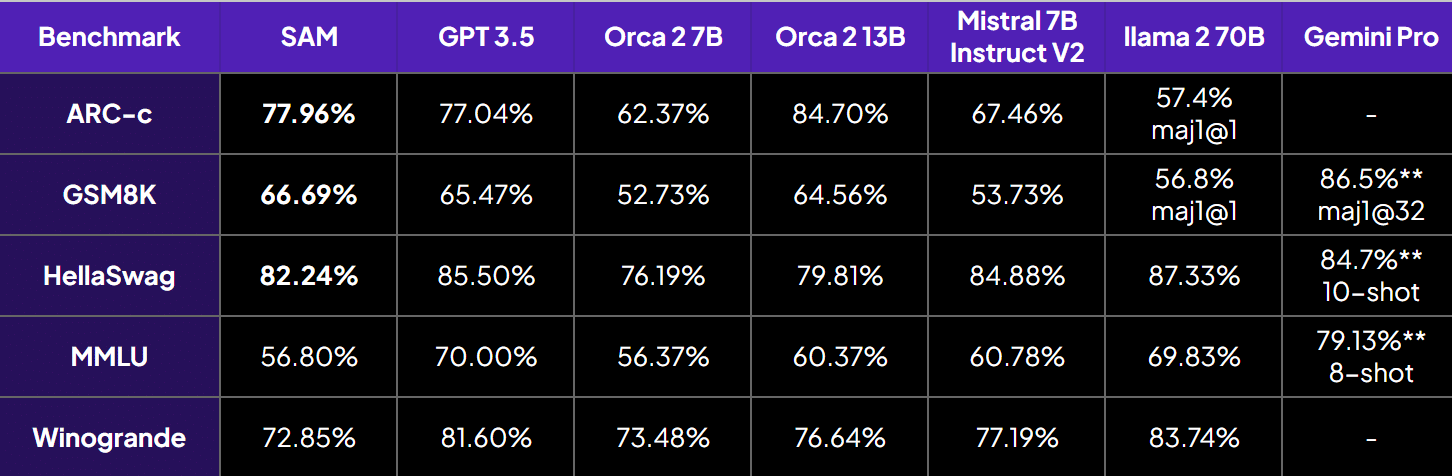
Note: Temperature=0.3 is the suggested for optimal performance
Run the model
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "SuperAGI/SAM"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
text = "Can elephants fly?"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Limitations
SAM is a demonstration that better reasoning can be induced using less but high-quality data generated using OpenSource LLMs. The model is not suitable for conversations and simple Q&A, it performs better in task breakdown and reasoning only. It does not have any moderation mechanisms. Therefore, the model is not suitable for production usage as it doesn’t have guardrails for toxicity, societal bias, and language limitations. We would love to collaborate with the community to build safer and better models.
The SuperAGI AI Team
Anmol Gautam, Arkajit Datta, Rajat Chawla, Ayush Vatsal, Sukrit Chatterjee, Adarsh Jha, Abhijeet Sinha, Rakesh Krishna, Adarsh Deep, Ishaan Bhola, Mukunda NS, Nishant Gaurav.