Explore
Featured models

kwaivgi / kling-v2.0
Generate 5s and 10s videos in 720p resolution

topazlabs / video-upscale
Video Upscaling from Topaz Labs

zsxkib / dia
Dia 1.6B by Nari Labs, Generates realistic dialogue audio from text, including non-verbal cues and voice cloning

fofr / color-matcher
Color match and white balance fixes for images

prunaai / hidream-l1-fast
This is an optimised version of the hidream-l1 model using the pruna ai optimisation toolkit!

nvidia / sana-sprint-1.6b
SANA-Sprint: One-Step Diffusion with Continuous-Time Consistency Distillation

wavespeedai / wan-2.1-i2v-480p
Accelerated inference for Wan 2.1 14B image to video, a comprehensive and open suite of video foundation models that pushes the boundaries of video generation.
easel / advanced-face-swap
Face swap one or two people into a target image
anthropic / claude-3.7-sonnet
The most intelligent Claude model and the first hybrid reasoning model on the market (claude-3-7-sonnet-20250219)

Fine-tune FLUX
Customize FLUX.1 [dev] with Ostris's AI Toolkit on Replicate. Train the model to recognize and generate new concepts using a small set of example images, for specific styles, characters, or objects. (Generated with davisbrown/flux-half-illustration.)
I want to…
Make videos with Wan2.1
Generate videos with Wan2.1, the fastest and highest quality open-source video generation model.
Generate images
Models that generate images from text prompts
Generate videos
Models that create and edit videos
Caption images
Models that generate text from images
Transcribe speech
Models that convert speech to text
Upscale images
Upscaling models that create high-quality images from low-quality images
Restore images
Models that improve or restore images by deblurring, colorization, and removing noise
Use a face to make images
Make realistic images of people instantly
Edit images
Tools for manipulating images.
Caption videos
Models that generate text from videos
Generate text
Models that can understand and generate text
Use official models
Official models are always on, maintained, and have predictable pricing.
Enhance videos
Models that enhance videos with super-resolution, sound effects, motion capture and other useful production effects.
Generate speech
Convert text to speech
Remove backgrounds
Models that remove backgrounds from images and videos
Use handy tools
Toolbelt-type models for videos and images.
Detect objects
Models that detect or segment objects in images and videos.
Generate music
Models to generate and modify music
Sing with voices
Voice-to-voice cloning and musical prosody
Make 3D stuff
Models that generate 3D objects, scenes, radiance fields, textures and multi-views.
Chat with images
Ask language models about images
Extract text from images
Optical character recognition (OCR) and text extraction
Get embeddings
Models that generate embeddings from inputs
Use the FLUX family of models
The FLUX family of text-to-image models from Black Forest Labs
Use FLUX fine-tunes
Browse the diverse range of fine-tunes the community has custom-trained on Replicate
Control image generation
Guide image generation with more than just text. Use edge detection, depth maps, and sketches to get the results you want.
Popular models

SDXL-Lightning by ByteDance: a fast text-to-image model that makes high-quality images in 4 steps
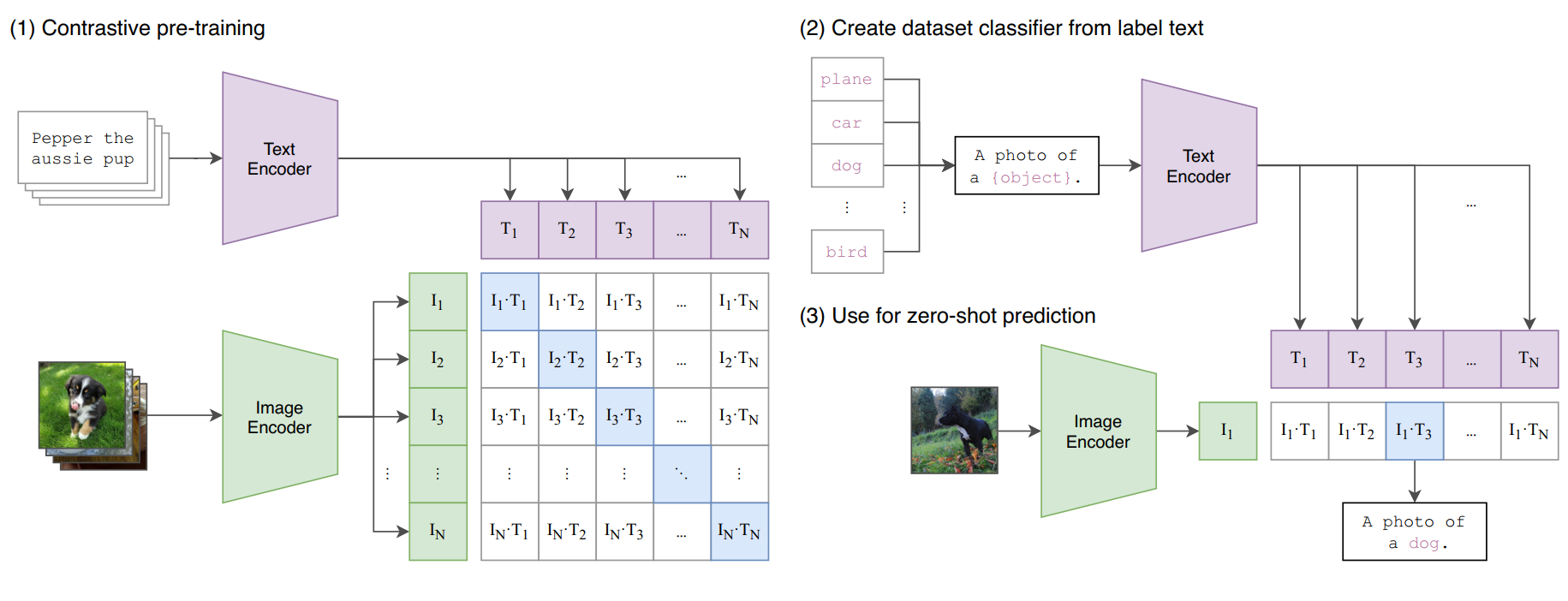
Generate CLIP (clip-vit-large-patch14) text & image embeddings


multilingual-e5-large: A multi-language text embedding model

Practical face restoration algorithm for *old photos* or *AI-generated faces*

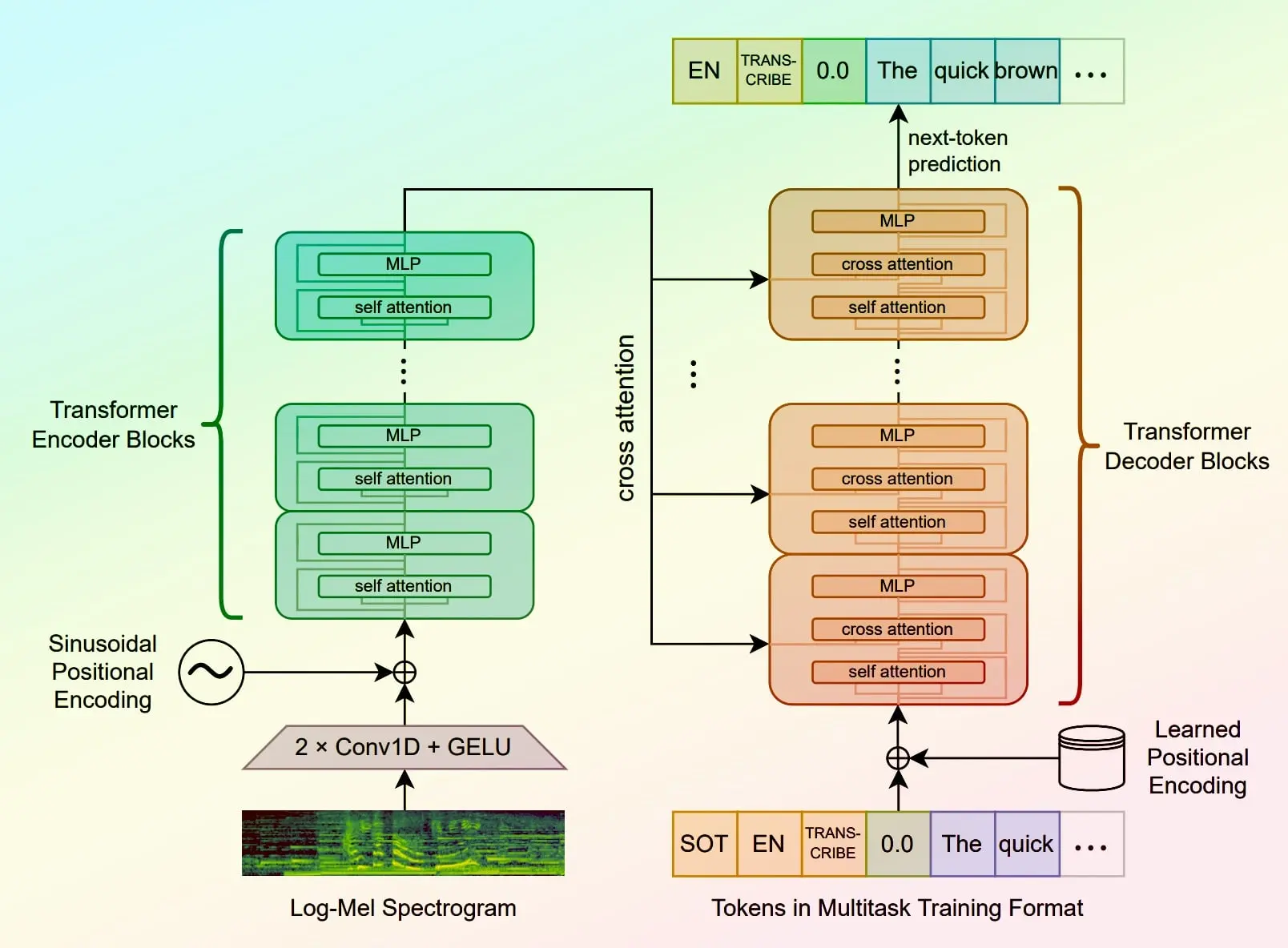
whisper-large-v3, incredibly fast, powered by Hugging Face Transformers! 🤗

High resolution image Upscaler and Enhancer. Use at ClarityAI.co. A free Magnific alternative. Twitter/X: @philz1337x
Latest models
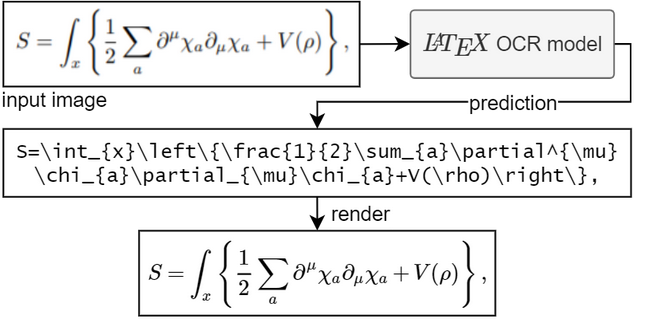
Optical character recognition to turn images of latex equations into latex format.


MAEST is a family of Transformer models based on PASST and focused on music analysis applications. The MAEST models are also available for inference in the Essentia library and for inference and training in the official repository.


Source: Nexusflow/NexusRaven-13B ✦ Quant: TheBloke/NexusRaven-13B-AWQ ✦ Surpassing the state-of-the-art in open-source function calling LLMs

Source: haoranxu/ALMA-7B ✦ Quant: TheBloke/ALMA-7B-AWQ ✦ ALMA (Advanced Language Model-based trAnslator) is an LLM-based translation model


An English, monolingual embedding model supporting 8192 sequence length (33M version)






T4 GPU, negative embeddings, img2img, inpainting, safety checker, KarrasDPM, pruned fp16 safetensor

T4 GPU, negative embeddings, img2img, inpainting, safety checker, KarrasDPM, pruned fp16 safetensor
A 7 billion parameter language model from Meta, fine tuned for chat completions

SDXL v1.0 - A text-to-image generative AI model that creates beautiful images





Tuning-Free Longer Video Diffusion via Noise Rescheduling

Zephyr-7B-beta, an LLM trained to act as a helpful assistant.

Monster Labs' Controlnet QR Code Monster v2 For SD-1.5 on top of AnimateDiff Prompt Travel (Motion Module SD 1.5 v2)

FILM: Frame Interpolation for Large Motion, In ECCV 2022.

Mistral-7B-v0.1 fine tuned for chat with the Dolphin dataset (an open-source implementation of Microsoft's Orca)

Mistral-7B-v0.1 fine tuned for chat with the Dolphin dataset (an open-source implementation of Microsoft's Orca)




A 40 billion parameter language model trained to follow human instructions.

An English, monolingual embedding model supporting 8192 sequence length (137M version)





Source: HuggingFaceH4/zephyr-7b-beta ✦ Quant: TheBloke/zephyr-7B-beta-AWQ ✦ Zephyr is a series of language models that are trained to act as helpful assistants. Zephyr-7B-β is the second model in the series
This is a cog implementation of "openbuddy-llemma-34b" 4-bit quantization model.

Mask prompting based on Grounding DINO & Segment Anything | Integral cog of doiwear.it


A 6B parameter open bilingual chat LLM (optimized for 8k+ context) | 开源双语对话语言模型


Openbuddy finetuned mistral-7b in GPTQ quantization in 4bits by TheBloke


A 8k sequence length text embedding set trained by Jina AI


MistralLiteA is a fine-tuned Mistral-7B-v0.1 language model, with enhanced capabilities of processing long context (up to 32K tokens)