
Readme
Upscale-A-Video: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution
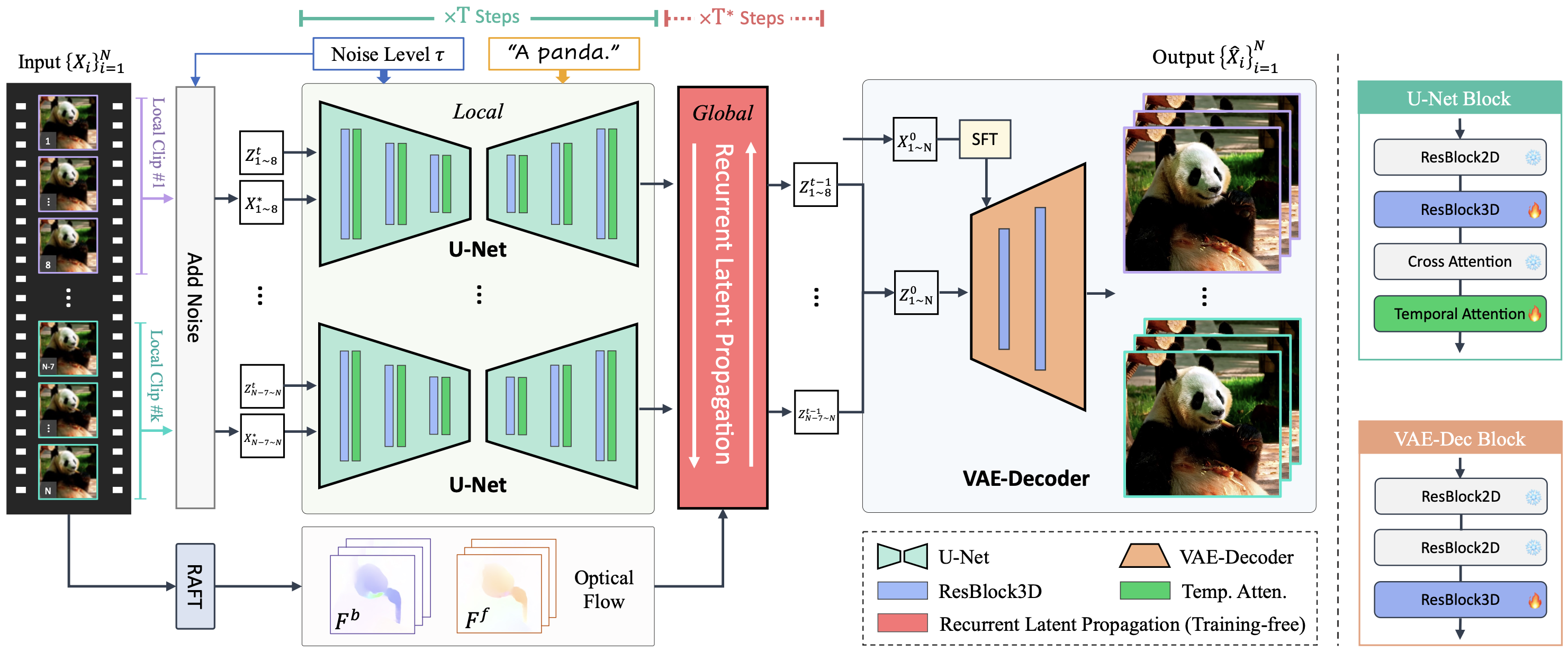
Upscale-A-Video is a diffusion-based model that upscales videos by taking the low-resolution video and text prompts as inputs.

🎬 Overview
📑 Citation
If you find our repo useful for your research, please consider citing our paper:
@inproceedings{zhou2024upscaleavideo,
title={{Upscale-A-Video}: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution},
author={Zhou, Shangchen and Yang, Peiqing and Wang, Jianyi and Luo, Yihang and Loy, Chen Change},
booktitle={CVPR},
year={2024}
}
📝 License
This project is licensed under NTU S-Lab License 1.0. Redistribution and use should follow this license.
📧 Contact
If you have any questions, please feel free to reach us at shangchenzhou@gmail.com or peiqingyang99@outlook.com.