Explore

Fine-tune FLUX fast
Customize FLUX.1 [dev] with the fast FLUX trainer on Replicate
Train the model to recognize and generate new concepts using a small set of example images, for specific styles, characters, or objects. It's fast (under 2 minutes), cheap (under $2), and gives you a warm, runnable model plus LoRA weights to download.
Featured models
minimax / hailuo-02
Hailuo 2 is a text-to-video and image-to-video model that can make 6s or 10s videos at 768p (standard) or 1080p (pro). It excels at real world physics.
minimax / hailuo-02-fast
A low cost and fast version of Hailuo 02. Generate 6s and 10s videos in 512p
bytedance / omni-human
Turns your audio/video/images into professional-quality animated videos
google / veo-3-fast
A faster and cheaper version of Google’s Veo 3 video model, with audio

google / veo-3
Sound on: Google’s flagship Veo 3 text to video model, with audio

flux-kontext-apps / kontext-emoji-maker
Use kontext to turn any image into an emoji, using a lora by starsfriday
wan-video / wan-2.2-t2v-fast
A very fast and cheap PrunaAI optimized version of Wan 2.2 A14B text-to-video

black-forest-labs / flux-krea-dev
An opinionated text-to-image model from Black Forest Labs in collaboration with Krea that excels in photorealism. Creates images that avoid the oversaturated "AI look".

wan-video / wan-2.2-i2v-a14b
Image-to-video at 720p and 480p with Wan 2.2 A14B
Official models
Official models are always on, maintained, and have predictable pricing.













I want to…
Generate images
Use AI To Generate Images & Photos with an API
Caption videos
Use AI To Caption Videos with an API
Generate speech
Convert text to speech
Use a face to make images
Make realistic images of people instantly
Generate videos
Use AI To Generate Videos with an API
Upscale images
Upscaling models that create high-quality images from low-quality images
Generate music
Use AI To Generate Music with an API
Edit images
Use AI To Edit Any Image with an API
Transcribe speech
Models that convert speech to text
Extract text from images
Optical character recognition (OCR) and text extraction
Remove backgrounds
Models that remove backgrounds from images and videos
Use the FLUX family of models
The FLUX family of text-to-image models from Black Forest Labs
Restore images
Models that improve or restore images by deblurring, colorization, and removing noise
Enhance videos
Upscaling models that create high-quality video from low-quality videos
Edit Videos
Tools for editing videos.
Videos from images
Use AI To Generate Videos from images with an API
Make videos with Wan
Generate videos with Wan, the fastest and highest quality open-source video generation model.
Use Kontext fine-tunes
Browse the diverse range of fine-tunes the community has custom-trained on Replicate
Caption images
Use AI To Caption Images with an API
Chat with images
Ask language models about images
Use LLMs
Models that can understand and generate text
Make 3D stuff
Models that generate 3D objects, scenes, radiance fields, textures and multi-views.
Use handy tools
Toolbelt-type models for videos and images.
Control image generation
Guide image generation with more than just text. Use edge detection, depth maps, and sketches to get the results you want.
Sing with voices
Voice-to-voice cloning and musical prosody
Get embeddings
Models that generate embeddings from inputs
Try for free
Get started with these models without adding a credit card. Whether you're making videos, generating images, or upscaling photos, these are great starting points.
Use official models
Official models are always on, maintained, and have predictable pricing.
Detect objects
Models that detect or segment objects in images and videos.
Use FLUX fine-tunes
Browse the diverse range of fine-tunes the community has custom-trained on Replicate
Popular models


Return CLIP features for the clip-vit-large-patch14 model

This is the fastest Flux Dev endpoint in the world, contact us for more at pruna.ai

whisper-large-v3, incredibly fast, with video transcription


SDXL-Lightning by ByteDance: a fast text-to-image model that makes high-quality images in 4 steps


Practical face restoration algorithm for *old photos* or *AI-generated faces*
Latest models





Fine-tuned version of the LLaMA-3.1-8B model, specifically optimized for tasks in finance, economics, trading, psychology, and social engineering.

whisper-large-v3, incredibly fast, with speaker diarization, powered by Hugging Face Transformers! 🤗




This project uses the Segment Anything 2 (SAM2) model to remove backgrounds from videos.


AI that transforms sketches into realistic images. Upload your drawing and describe it in the prompt. You can also adjust the ControlNet parameters and scale the image to a higher resolution for better results


SOTA open-source model for chatting with videos and the newest model in the Qwen family

Accelerated transcription, word-level timestamps and diarization with whisperX large-v3 for large audio files

Accelerated transcription, word-level timestamps and diarization with whisperX large-v3






ControlNet for FLUX.1-dev model jointly released by InstantX and Shakker Labs

InternLM-XComposer-2.5: A Versatile Large Vision Language Model Supporting Long-Contextual Input and Output


Virtual try-on using Stable Diffusion and IP-Adapter

replace background with Stable Diffusion and ControlNet



Join the Granite community where you can find numerous recipe workbooks to help you get started with a wide variety of use cases using this model. https://github.com/ibm-granite-community
Turn text from the law in Spanish to structured data to feed support building a knowledge graph

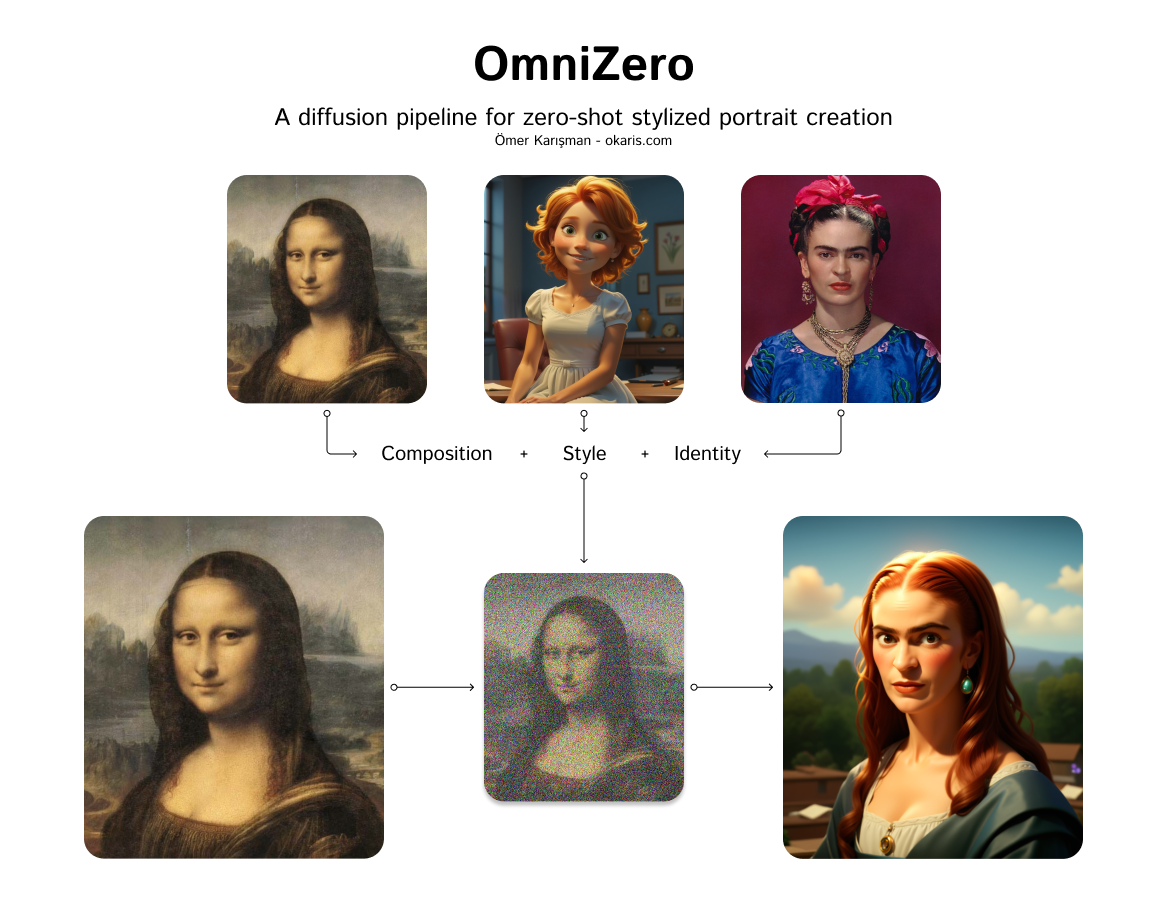
Omni-Zero: A diffusion pipeline for zero-shot stylized portrait creation.







Join the Granite community where you can find numerous recipe workbooks to help you get started with a wide variety of use cases using this model. https://github.com/ibm-granite-community

