Explore
Featured models

zsxkib / pyramid-flow
Text-to-Video + Image-to-Video: Pyramid Flow Autoregressive Video Generation method based on Flow Matching

black-forest-labs / flux-1.1-pro
Faster, better FLUX Pro. Text-to-image model with excellent image quality, prompt adherence, and output diversity.

black-forest-labs / flux-schnell
The fastest image generation model tailored for local development and personal use

black-forest-labs / flux-dev
A 12 billion parameter rectified flow transformer capable of generating images from text descriptions

levelsio / analog-film
Take photos in analog film style
meta / meta-llama-3.1-405b-instruct
Meta's flagship 405 billion parameter language model, fine-tuned for chat completions
I want to…
Generate images
Models that generate images from text prompts
Use a language model
Models that can understand and generate text
Caption images
Models that generate text from images
Edit images
Tools for manipulating images.
Restore images
Models that improve or restore images by deblurring, colorization, and removing noise
The FLUX.1 family of models
The FLUX.1 family of text-to-image models from Black Forest Labs
Upscale images
Upscaling models that create high-quality images from low-quality images
Get embeddings
Models that generate embeddings from inputs
Extract text from images
Optical character recognition (OCR) and text extraction
Transcribe speech
Models that convert speech to text
Chat with images
Ask language models about images
Use handy tools
Toolbelt-type models for videos and images.
Use a face to make images
Make realistic images of people instantly
Generate music
Models to generate and modify music
Generate videos
Models that create and edit videos
Fine-tune Flux
Create a fine-tuned Flux model using your own training images.
Generate speech
Convert text to speech
Make 3D stuff
Models that generate 3D objects, scenes, radiance fields, textures and multi-views.
Get structured data
Language models that support grammar-based decoding as well as jsonschema constraints.
Popular models

SDXL-Lightning by ByteDance: a fast text-to-image model that makes high-quality images in 4 steps

Fine-Tuned Vision Transformer (ViT) for NSFW Image Classification




Practical face restoration algorithm for *old photos* or *AI-generated faces*

The LaMa (Large Mask Inpainting) model is an advanced image inpainting system designed to address the challenges of handling large missing areas, complex geometric structures, and high-resolution images.
Latest models




DO NOT USE - Broken - Only Public For API Usage & Debugging

Upscale images with the latent diffusion superresolution model


Generate an image using text by visualizing CLIP features.



MAT: Mask-Aware Transformer for Large Hole Image Inpainting
Artistic Radiance Fields - Transfer the style of an image to a 3D scene (NeRF)


High-Resolution Image Synthesis with Latent Diffusion Models
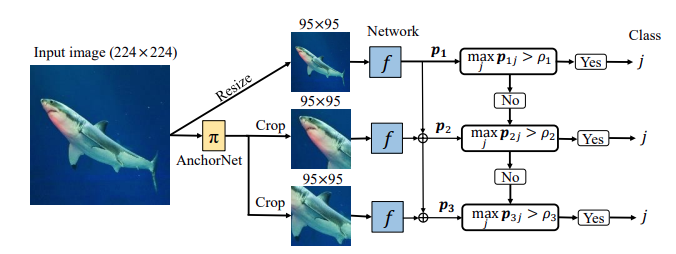
Localizing Semantic Patches for Accelerating Image Classification

Lightweight Bimodal Network for Single-Image Super-Resolution via Symmetric CNN and Recursive Transformer



Made public only for API calls. Use min-dalle instead-- it's superior.


Generate petitions suitable for sending to the UK government





An open-source model for program synthesis. Competitive with OpenAI Codex.



Thin-Plate Spline Motion Model for Image Animation

A 1.4B parameter text2im model from CompVis, finetuned on CLIP text embeds and curated data.

Facial Expression Recognition using Residual Masking Network

Transfer the texture/style of one image onto another






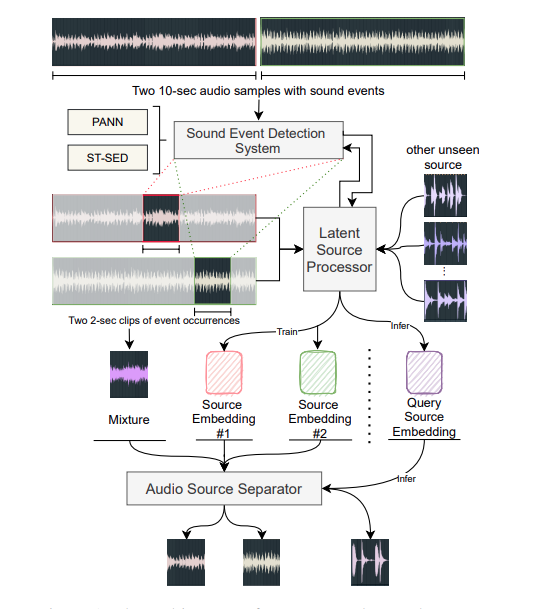
Zero shot Sound separation by arbitrary query samples
